
How we at dvloper.io build enterprise agentic AI that actually ships, and why the model isn't where your agent lives or dies.
Every enterprise AI program starts with the same enthusiasm and ends with the same question: “Why does the demo look so sharp and the production pilot look like a toddler with a search engine?”
We see this constantly. A team picks a model, wires it to a handful of tools, builds a nice chat UI, and ships something that crushes the happy-path scenarios the product owner demoed. Then it meets real enterprise data, real business rules, real ambiguity, and it collapses. Outputs drift. Trust erodes. The project quietly gets re-labeled as “exploratory” and everyone pretends the roadmap always had that caveat.
The thing nobody wants to say out loud is this: the LLM is not where your agent lives or dies. The model is a commodity. GPT, Claude, Gemini, Llama. Swap them, benchmark them, argue about them on Twitter. None of it will save an agentic system that doesn't understand your enterprise.
The layer that actually determines whether your agent survives contact with production is the one underneath the model. The one that tells it what your enterprise actually means.
That layer is an ontology. And building it properly is what we do at dvloper.io.
What a production-grade enterprise agent actually requires
When we talk about agentic AI at dvloper.io, we mean something very specific: a system that encodes the data, logic, actions, and security of the enterprise into a coherent semantic model, and then lets humans and agents operate on top of it with full fidelity. We call the capability we build for our clients the AI Agentic Factory, and it rests on four things, not one.
Strip away the buzzwords, and an enterprise-grade agent has to do four jobs simultaneously:
- Encode the data of the enterprise. Unify the vast and fragmented sources of truth: CRM, ERP, systems of record, ticketing platforms, document stores, operational telemetry, into coherent objects, properties, and links. Not a dashboard. Not an API gateway. A single semantic model the agent can actually reason over.
- Capture the logic of the enterprise. The rules, constraints, and decision frameworks currently living in someone's head, in a PDF from 2022, or worse, buried in fifteen different stored procedures nobody has touched since the person who wrote them left. Encoded once. Consistent everywhere.
- Model the actions of the enterprise as first-class primitives. Not just “the agent can generate an answer,” but “the agent can write back to the system of record, with the right approvals, the right audit trail, and the right rollback path.” Simple transactions and multi-step workflows, both governed the same way.
- Govern both humans and agents under one security model. Same identity, same permissions, same audit logs, whether the actor is a senior analyst or an autonomous agent. No CISO is going to sign off on “the LLM decided what was allowed.”
None of that is LLM work. All of it is semantic-layer work. And it is exactly what most agentic AI programs skip in the rush to ship a demo, which is exactly why most agentic AI programs stall between demo and production.
Why agents fail without a semantic layer
Let's be specific about what actually breaks when you skip the ontology.
1. The same term means five different things. A “customer” in CRM is not the same as a “customer” in billing, is not the same as a “customer” in the churn model, is not the same as the entity your contract says you owe money to. Your agent sees all five and averages them.
2. Business rules live in humans, not systems. The rule that “we never onboard vendors from jurisdiction X without a Tier-2 compliance review” exists in someone's head and in a PDF from 2022. Your agent has no idea.
3. The agent can't tell when it doesn't know. This is the failure mode that destroys enterprise trust faster than any other. An agent that confidently answers with incomplete information is worse than no agent at all, because you stop checking it.
4. Nothing is explainable. When the agent produces a decision, nobody can reconstruct why. No auditor will sign off on that. No compliance team will let it run unsupervised. No regulator will let it touch a regulated workflow.
5. Every new use case is a from-scratch rebuild. Without a shared semantic backbone, each agent is its own snowflake. Pilots never become platforms. Year two looks exactly like year one except with more sunk cost.
These are not model problems. No amount of swapping from GPT-4 to Claude to Gemini to Llama will fix them. They are architectural problems, and the architecture is the ontology.
How we actually build these systems
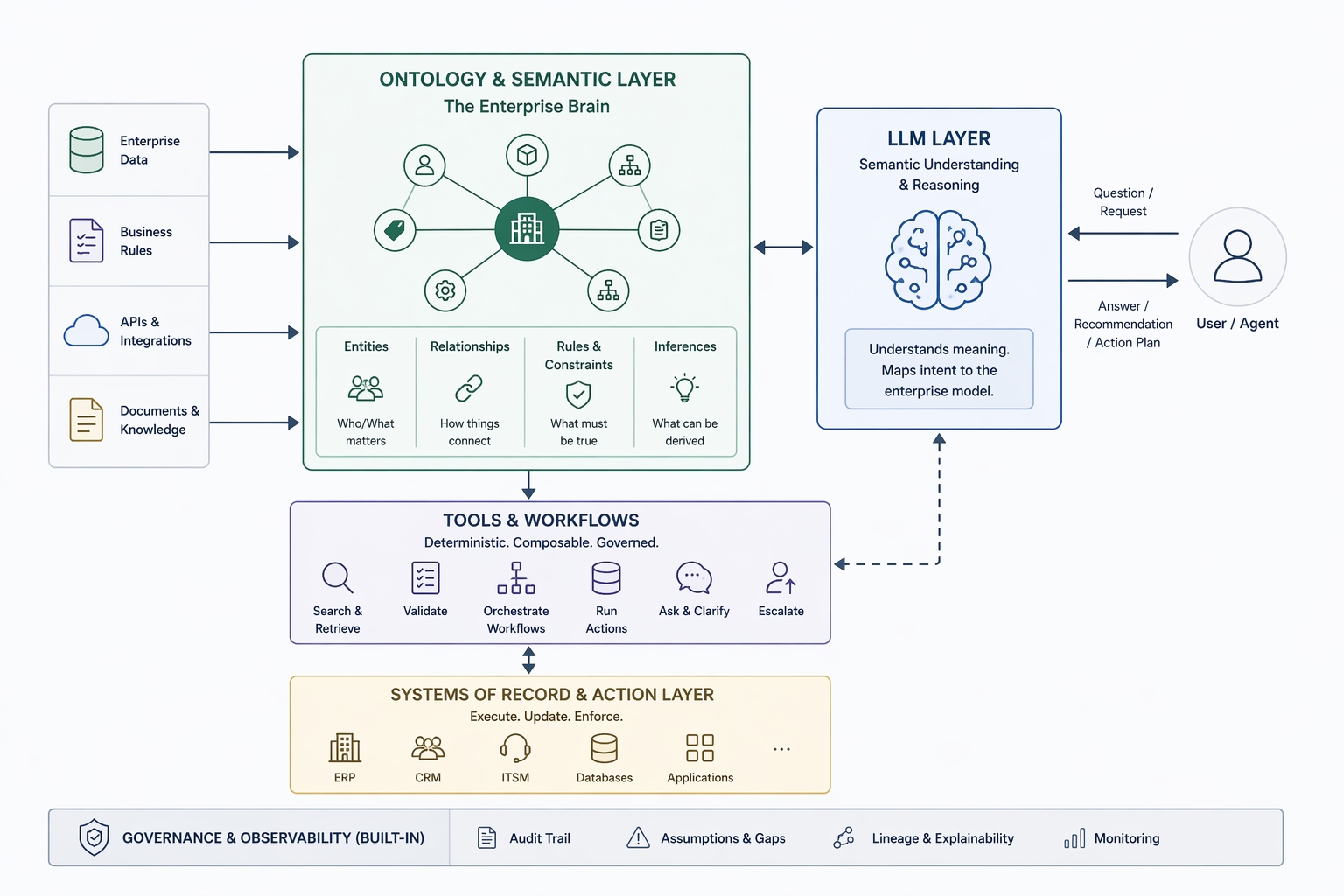
Here is the pattern we use at dvloper.io, and what makes the Agentic Factory approach different from “hook an LLM to LangChain and hope.”
1. Ontology-first, model-second
Before we pick the LLM, we model the domain. What are the entities? What are the relationships? What are the rules, constraints, and required properties? What does “done” look like for each workflow? What does every actor (human or agent) needs to know to make a safe decision?
This is boring, unglamorous, diagram-heavy work. It is also exactly what separates the systems that ship from the ones that don't.
2. The agent's job is semantic translation, not answer generation
Once the ontology exists, the LLM's job gets narrower than people expect. It is not “generate the answer.” It is: take the user's request, map it to ontology concepts, identify what is being asked, and route to the right tools.
That is a much more tractable problem for an LLM. It is also much easier to make reliable, testable, and debuggable. Most of what people call “hallucination” in production agents is actually the LLM being asked to do a job the architecture should have handled for it.
3. Tools are first-class citizens, and they are boring on purpose
We build tools as small, deterministic, testable pieces of code that the agent composes into workflows. Boring tools are good tools. They fail predictably. They log cleanly. They don't hallucinate.
The tools that show up in every ontology-driven agent we build:
- The Gap Capture tool. Identifies what is missing before the agent acts. If an onboarding request does not have a jurisdiction, the agent does not guess. It records the gap.
- The Question Generation tool. Turns gaps into targeted follow-up questions, grounded in the ontology rather than generic “can you clarify?” prompts. “Is this vendor operating in a restricted jurisdiction?” beats “Tell me more about the vendor” every time.
- The Assumption Logging tool. When a workflow has to proceed with a temporary assumption, the agent records it explicitly. Every decision becomes auditable. Every assumption becomes a conversation the team can later have.
- The Validation tool. Checks that requests and resolved entities satisfy ontology constraints before any action is taken. Every contract must be linked to a legal entity. Every change request must have a rollback path. Every product must have a capability owner. The ontology says so; the validator enforces it.
- The Reasoning tool. Applies rules over ontology relationships to derive facts the input didn't explicitly contain: eligibility, risk tier, dependency chains, blast radius. This is where ontology stops being a dictionary and starts being an inference engine.
- The Escalation tool. When the agent can't safely complete a task, it routes to a human with full context (gaps, assumptions, partial work, recommended next actions), not a generic ticket with “agent failed, please investigate.”
These are the tools that make the difference between an agent that answers fast and an agent you would actually put in front of a regulator.
4. Observability on top, governance on the side
Every agent call, every tool invocation, every assumption, every escalation, all logged, queryable, auditable. This is not bolted on at the end. It is part of the architecture from day one. When an agent makes a decision six months from now, you can reconstruct exactly why.
5. The platform compounds
This is where the “Factory” in Agentic Factory matters. The first agent we build comes with a semantic model, a tool library, and observability plumbing. The second agent reuses all of it. By the third or fourth use case, the incremental cost of a new agent is a fraction of the first one.
That is when agentic AI stops being a project and starts being a capability.
A real example: agent-driven network operations
Some of our most demanding work lives in network operations: proactive monitoring, configuration validation, incident triage. Real-time, high-stakes, zero-tolerance-for-wrong-answers territory. An agent that confidently pushes a bad change into a production network does not produce a bug. It produces an outage with a name.
What does ontology look like here?
- Entities: devices, interfaces, links, policies, tenants, service paths, SLAs, maintenance windows.
- Relationships: which device serves which tenant, which policy applies to which interface, which link is primary versus backup, which tenant shares which blast radius.
- Rules: what constitutes a valid configuration change, what requires tenant approval, what can be auto-remediated, what must never be touched outside a maintenance window.
A traditional agent asked “Can we push this configuration change?” might confidently answer yes based on syntactic validation alone. That is dangerous.
An ontology-driven agent answers a different question entirely: given the ontology of this network, is this change safe, for which tenants, with what downstream effects, and what assumptions is it making?
It might conclude:
Change validation: Blocked.
Gaps detected:
• Affected tenant SLA window not confirmed
• Rollback path for interface bundle not verified
• Peer link redundancy currently degraded
Questions requiring human input:
• Is this change scheduled inside the tenant's approved maintenance window?
• Has the peer-side team acknowledged the redundant-link status?
Assumptions logged:
• Tenant SLA tier inferred from most recent service catalog snapshot
• Rollback path assumed to be the previously-deployed configuration baseline
Recommended next actions:
• Route to on-call network engineer with full context
• Hold change until peer-side redundancy restored
That is not a chatbot. That is a co-worker with enough context to be trustworthy, and enough self-awareness to escalate when it shouldn't proceed alone.
The business case, said plainly
The reason this architecture is worth the upfront work is not theoretical. It shows up in five places:
Trust. The agent shows what it knows, what it doesn't know, and why. Users stop second-guessing outputs, which means they actually start using them.
Explainability. Every decision is grounded in ontology, rules, and traceable gaps. Regulators, auditors, and internal risk teams can follow the reasoning end-to-end.
Reusability. The ontology becomes a shared asset across every agent and workflow you build. Second use case costs a fraction of the first.
Governance. Assumptions, questions, unresolved issues, and escalations are explicitly captured, not hidden inside model weights you cannot inspect.
Scalability. Different domain agents share the same semantic backbone. Your platform grows as a coherent system instead of a collection of disconnected pilots.
These are not theoretical benefits. They are the reason enterprises that adopt this pattern end up with agentic AI running in production, and the ones that don't end up with a graveyard of demos.
The closing thought
LLMs are excellent at generating language. Enterprise decisions require structure, meaning, constraints, and the discipline to recognize when an answer is incomplete. One of those things is a commodity in 2026. The other is the work.
At dvloper.io, the work is what we sell. The ontology-driven agent is not a demo pattern for us. It is how we ship.
If you are stuck somewhere between a promising POC and a production agent you'd actually trust with a regulated workflow, the missing layer is probably not a better model. It is the ontology underneath.
We would be happy to talk about yours.
Want to discuss where your agentic AI program is stuck, or how an ontology-first architecture would fit your stack? Get in touch at dvloper.io.
Razvan Georgescu, VP of Data & AI, dvloper.io